Langchain, LlamaIndex 와 같이 잘 만들어진 LLM applications 프레임워크 덕분에 주어진 데이터에 대하여 RAG(Retrieval Augmented Generation) 시스템을 구축하는 것은 굉장히 쉬워졌다. 그러나 쉬워진 구축 난이도에 비해 RAG 성능을 상용화 가능한 수준까지 끌어올리는 것은 아직도 갈 길이 멀다. 가지고 있는 데이터의 특성에 따라 적합한 RAG 기법 및 파라미터도 달라지고, 도메인의 특성에 따라 쿼리로부터 SQL을 얼마나 잘 다루는지, 테이블로 주로 구성된 데이터를 어떻게 전처리 할 것인지 등 고려해야 할 요소가 많다. 케이스별로 달라지는 경우가 많고, 여러 시행착오가 필요한 기술이기 때문에 다른 기업들의 시행착오 및 실험 시 유용했던 방법론들을 참고하는 것은 매우 도움이 된다.
OpenAI 에서는 RAG 에 적용하여 효과를 보았던 방법론들을 영상을 통해 공유한 적이 있었는데, 10개월 정도 전의 자료이기 때문에 최신 방법론이 아니라서 아쉬움이 있었다. 그러나, OpenAI 에서 직접 실험한 내용들을 공유한 영상이기 때문에 참고해 보면 도움이 될 것 같다.
이번 Anthropic 에서도 비슷하게 RAG 실험 결과를 공유하는 블로그가 얼마 전 올라와서 그 내용을 정리하여 공유하려고 한다. 원문은 아래 링크를 참조하면 되고, 내용을 그대로 옮기는 것이 아닌 내용을 수정, 보완하여 작성하였다.
참고: https://www.anthropic.com/news/contextual-retrieval
Introducing Contextual Retrieval
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
www.anthropic.com
1. Intro
1.1. 기존 RAG 의 문제
RAG 를 사용하여 LLM 모델이 가진 지식을 보완하는 것은 이제 상당히 일반화 된 방법이다. RAG 는 데이터베이스, 외부 지식 등에서 관련 정보를 검색하여 사용자의 프롬프트에 추가하는 방법이다. 문제는 RAG 솔루션이 정보를 인코딩할 때 (문서 전처리, 청킹 및 임베딩 등) 컨텍스트를 제거하기 때문에 시스템이 적합한 관련 정보를 제대로 검색하지 못하는 경우가 많다는 것이다. Anthropic 은 이러한 Retrieval 성능 문제를 해결하기 위해 Contextual Retrieval 방법을 설명하고 있다. 이 방법에는 Contextual Embeddings 와 Contextual BM25 라는 Hybrid Search 기술을 사용하고 있고, 이 방법을 사용하여 실패한 검색 수를 49% 까지 줄였으며, reranker 까지 결합하여 67% 까지 줄였다고 한다.
1.2. Long Context
한동안 LLM 의 context window 길이가 경쟁적으로 매우 길어짐에 따라 RAG 기술이 더 이상 필요 없어지는 것은 아닌가 하는 얘기가 많이 들렸었다. 실제로 200,000 토큰 길이의 context window 인 경우, 약 500 페이지 분량의 자료이기 때문에 지식 시스템에서 검색해서 관련 정보를 가져오는 것이 아닌 모든 정보를 context 에 포함하면 될 것 처럼 보였다. 그러나 생각보다 context window 확장은 확장성 측면에서 한계가 있고, 여전히 RAG 시스템은 유용한 방법론인 것 같다. 특히, 특정 task 를 수행하는 agent 측면에서는 아직도 필요한 정보만을 정제하여 LLM 에 주입해주는 방식이 가장 유효하다고 생각한다.
물론 context window 내에서 소화 가능한 문제는 모두 집어넣는 것이 제일 좋은데, 이를 위해 Anthropic 에서는 Claude 를 위한 프롬프트 캐싱을 출시하였다. API 호출에서 자주 쓰이는 프롬프트를 캐싱하여 시간을 2배 이상 줄이고 비용을 최대 90% 까지 줄이는 것이 가능해졌다.
2. RAG
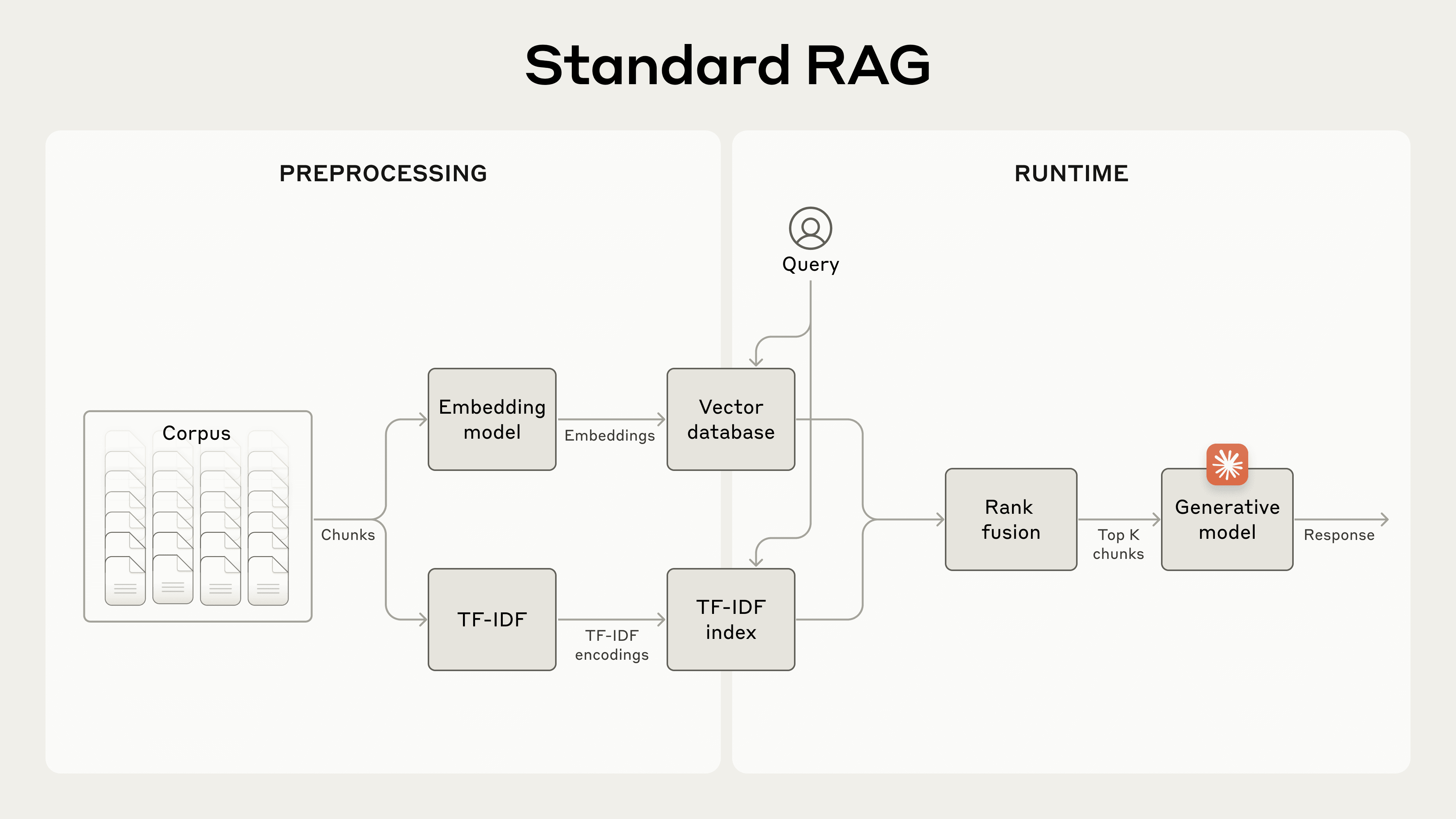
2.1. Standard RAG
Standard RAG 에 대한 설명 및 문제점에 대해 설명한다. RAG 는 일반적으로 아래 단계로 이루어진다.
- 코퍼스를 특정 chunk size 단위로 나눈다. 이 때 청크 간 일부 overlap 을 두어 문맥이 일부 유지될 수 있도록 한다.
- 임베딩 모델을 사용하여 청크를 벡터로 임베딩한다.
- 벡터 데이터베이스에 저장하고, similarity search 를 통해 검색 시 쿼리와 유사한 청크를 가져올 수 있도록 한다.
이전 작성한 BM25 분석하기 문서에서도 얘기하였지만 임베딩 모델은 의미적 관계를 잡아내는 데 뛰어나지만 term 기반 중요한 항목을 놓칠 수 있다. 그래서 BM25(Best Matching 25) 기술과 결합하여 Hybrid Search 방식으로 검색을 구현하는 것이 일반적이다. 하지만 이렇게 하더라도 RAG 시스템에는 한계가 존재한다.
2.2. The context conundrum
문서의 길이는 보통 매우 길기 때문에 효율적인 검색 및 LLM 이 소화할 수 있는 청크 단위로 나누게 되는데, 이 때 개별 청크에 충분한 컨텍스트가 없는 경우가 발생하게 된다. 예를 들어, financial information (U.S. SEC filings) 문서에서 아래와 같은 질의가 들어온 경우, 청크만으로는 언급하는 회사나 관련 기간을 별도로 지정하지 않아서 올바른 검색 결과를 가져오거나 가져오더라도 그 정보를 효과적으로 사용하기 어려울 수 있다.
"What was the revenue growth for ACME Corp in Q2 2023?"
3. Contextual Retrieval
Contextual Retrieval 은 청크에 임베딩하기 전에 청크별 설명하는 context 를 앞에 붙이고 BM25 인덱스를 생성하여 문제를 해결한다. 위 문제에서 context 를 고려하여 청크를 다시 만들면 아래와 같다.
original_chunk = "The company's revenue grew by 3% over the previous quarter."
contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."기본 RAG 에서 사용하는 청킹 방식으로는 검색으로 가져온 original chunk 에 질의에 대한 답이 있다 하더라도 context 가 없기 때문에 어떤 회사, 기간에 대한 정보인지 불명확하여 경우에 따라 잘못된 정보를 답변할 수도 있다. 반면, context 를 고려한 청크는 이 청크가 어떤 문서에서 왔는 지, 어떤 내용에 관한 것인지 등을 추가적으로 담고 있는 것을 알 수 있다. 기존에 이러한 context 를 담는 방식은 청크에 문서의 요약을 추가적으로 붙이는 방법으로 시도가 되었었는데, Anthropic 실험 결과로는 약간의 성능 이득 밖에 볼 수 없었다고 한다. 또한, 잘 알려진 HyDE 방식이나 문서 요약문으로 청크 색인을 하는 것은 성능이 낮았다고 한다.
기존 청크에 추가적인 context 를 담는 것은 별도 LLM 호출과 같은 비용이 추가로 발생하기 때문에 성능 이득이 적거나 없다면 실제 적용하긴 어려울 것이다. Anthropic 은 색인에 추가적인 비용을 부담하는 만큼 context 작성을 고도화하여 실패한 검색 수를 49% 까지 줄였으며, reranker 까지 결합하여 67% 까지 줄여 확실한 성능 이득을 확보하였다.
3.1. Implementing Contextual Retrieval
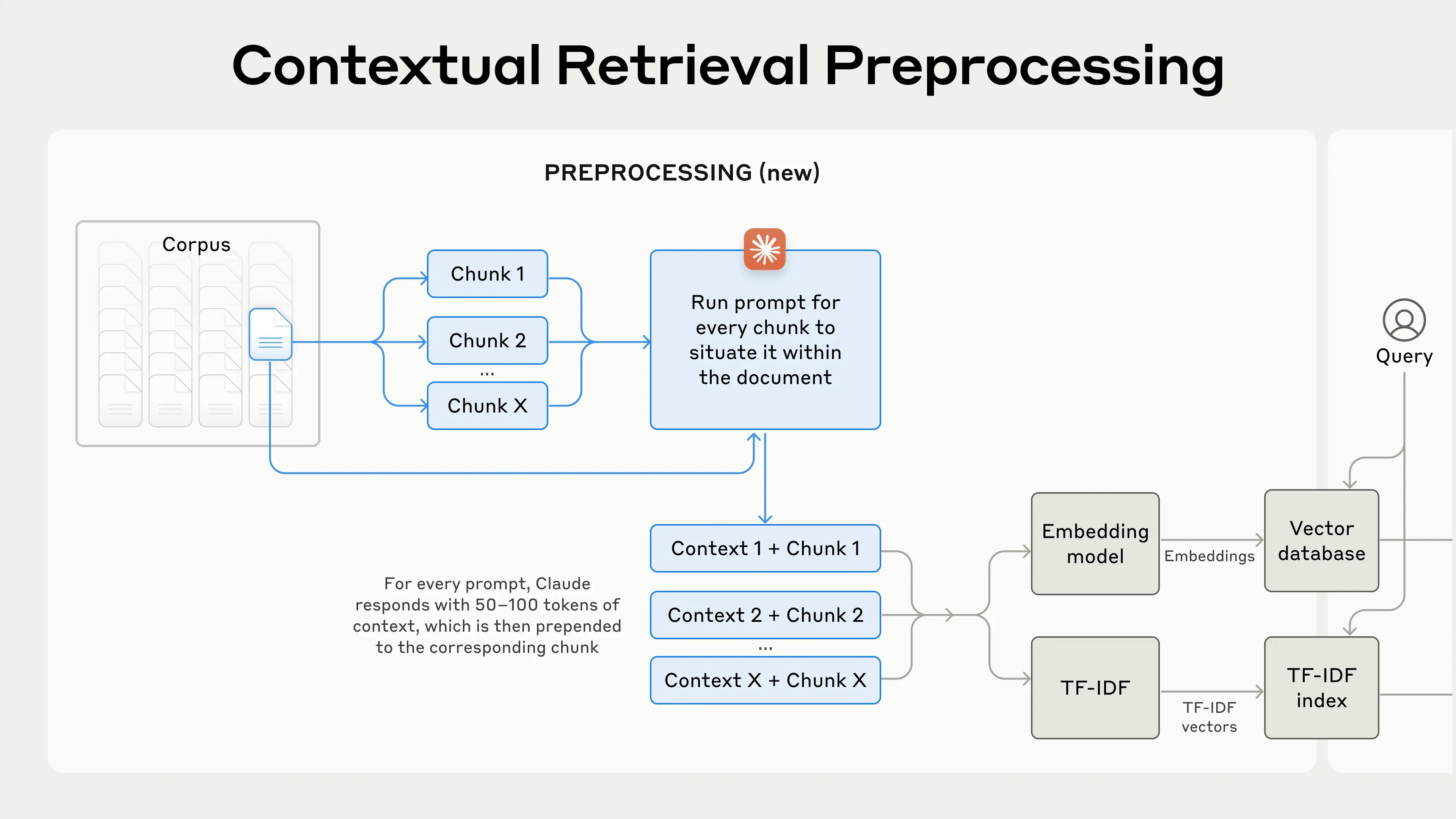
수천 개 또는 수백만 개의 청크에 context 를 수동으로 달기에는 너무나 많은 작업이 필요하기 때문에 Claude 를 사용하여 청크의 context 를 작성한다. 실제 생성된 context 는 대략 50 ~ 100 개 정도의 토큰으로 구성되었고, 위 이미지에서 알 수 있듯 context 까지 포함되어 BM25 및 Vector 인덱싱을 진행하였다고 한다. 상대적으로 코스트 비용이 적은 모델인 Claude 3 Haiku 모델을 사용하였고, 아래 프롬프트를 사용하여 청크를 설명하고 청크별 맥락을 제공하는 context 를 생성하였다. 특히, 프롬프트를 보면 {WHOLE_DOCUMENT} 로 긴 문서 전체가 들어가는 것을 알 수 있는데, 이는 Anthropic 이 200,000 토큰까지 지원하는 강력한 모델을 가지고 있기에 가능한 시도로 보인다.
- Claude 3 Haiku: Smarter, faster, and more affordable than other models in its intelligence category.
- Customer interactions: quick and accurate support in live interactions, translations
- Content moderation: catch risky behavior or customer requests
- Cost-saving tasks: optimized logistics, inventory management, extract knowledge from unstructured data
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else. 3.2. Contextual Retrieval 의 성능
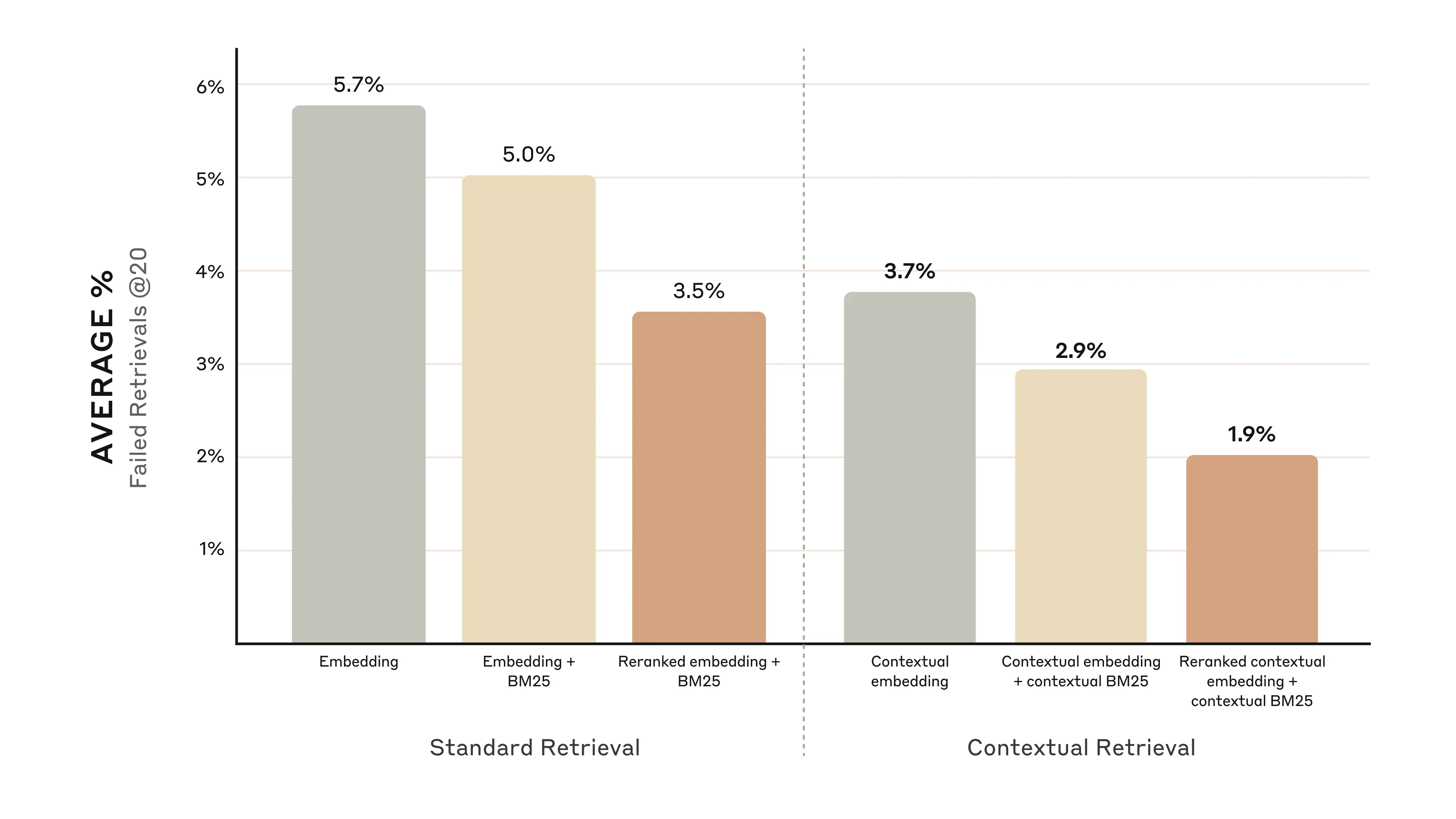
다양한 도메인 (codebases, fiction, ArXiv papers, Science Papers) 에 대하여 실험을 진행하였고, 상위 20개의 검색 청크에 대하여 평가를 진행하였다. 평가 지표로는 1 - recall@20 지표를 사용하였는데, 이는 상위 20개 청크로도 관련 문서 검색에 실패한 케이스의 비율을 측정한다.
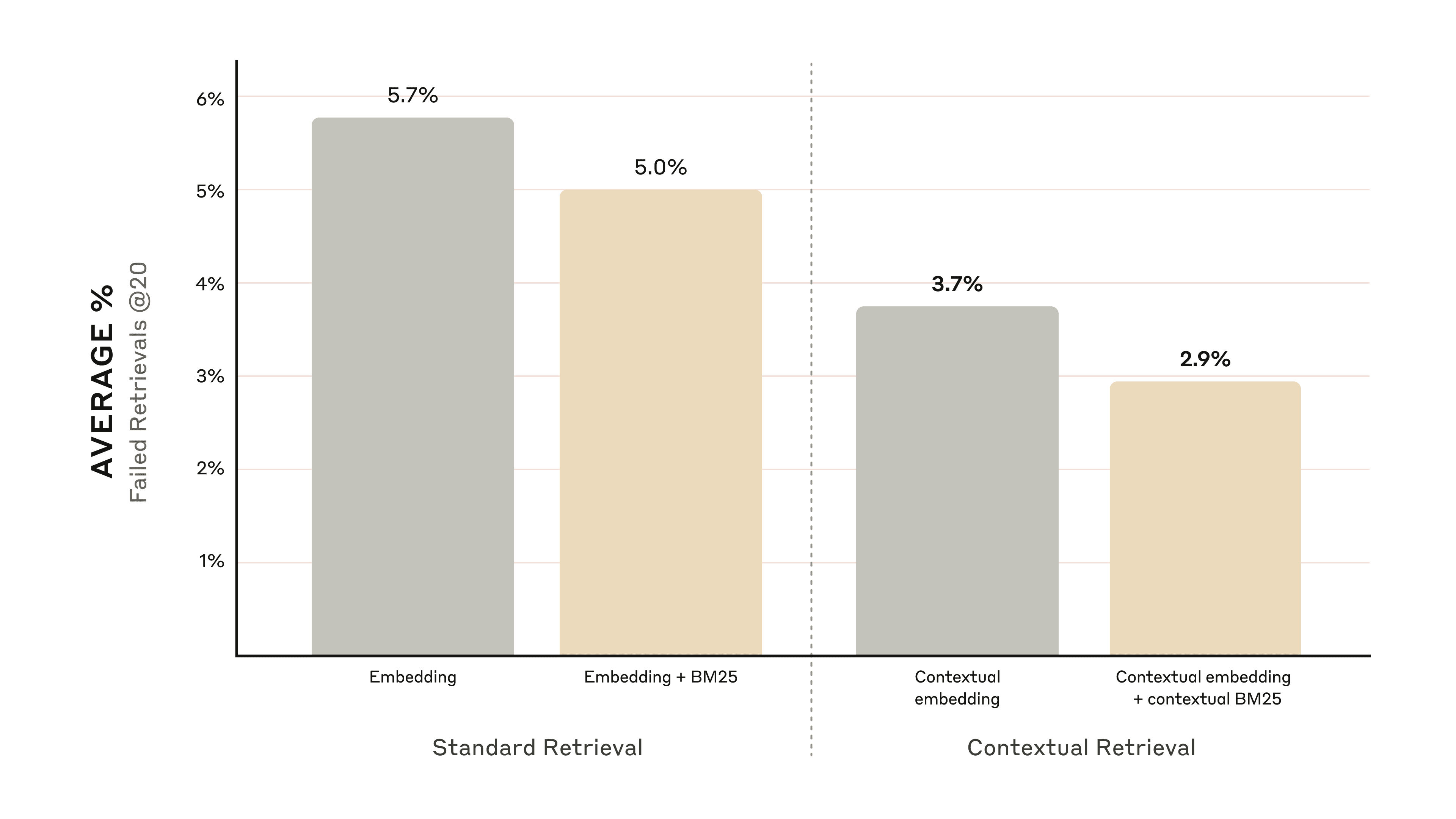
- contextual embeddings 는 상위 20개 청크 검색 실패율을 35% 줄였다. (5.7% -> 3.7%)
- contextual embeddings 와 contextual BM25 를 함께 사용하면 상위 20개 청크 검색 실패율이 49% 감소한다. (5.7% -> 2.9%)
3.3. 구현 시 고려 사항
- 청크 분할: 청킹 방법에 대한 고민이 필요하다. (다양한 청킹 전략 관련 문서: https://www.pinecone.io/learn/chunking-strategies/) 청크 사이즈, 청크 바운더리 및 청크 오버랩 등의 파라미터는 검색 성능에 영향을 미친다.
- 임베딩 모델: contextual retrieval 방식을 사용하면 모든 임베딩 모델에서 성능 향상을 볼 수 있었지만, 특히 성능 향상이 두드러지는 모델이 있었다. 도메인에 맞게 적합한 임베딩 모델이 존재할 수 있으며, 실험에서는 Gemini 와 Voyage 임베딩이 특히 효과적이었다고 한다.
- 커스텀 문맥 프롬프트: 위에서 제공된 프롬프트는 일반적인 포맷이고, 적용하려는 도메인에 맞게 조정된 프롬프트를 사용하는 것이 더욱 효과적이다. 예를 들어, 타겟팅하려는 특정 문서에만 정의되어 있는 주요 용어에 대한 용어집을 프롬프트에 반영할 수도 있다.
- 청크 수: 컨텍스트에 청크를 더 많이 추가하면 관련 정보를 포함할 가능성이 높아진다. 실험에서는 5, 10, 20개의 청크를 사용해보았고, 이 중 20개의 청크를 사용하는 것이 제일 성능이 좋았다고 한다. 하지만 이 부분은 아직 실험이 더 필요한 부분이고 도메인 특성이나 내가 분할한 청크 특성에 따라 달라질 수 있는 요인이라고 생각한다.
4. Reranking 사용
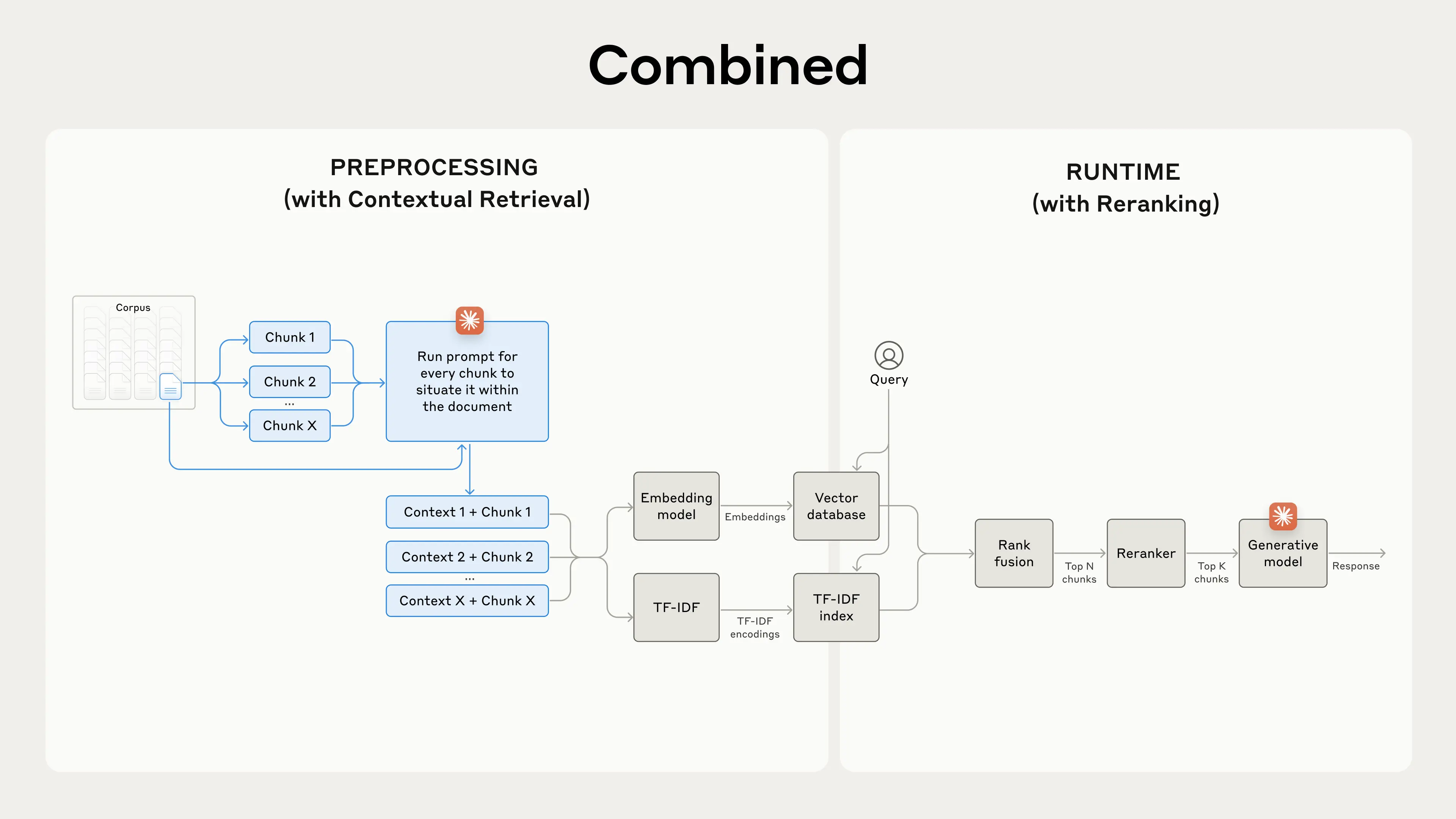
일반적으로 RAG 시스템을 구축할 때 retrieval 된 결과에 추가적으로 reranker 를 적용했을 때 성능 향상을 보이는 경우가 많다. 왜냐하면 일반적으로 vector search 기반으로 검색할 때는 bi-encoder 기반의 임베딩 모델을 사용하는데, bi-encoder 모델은 쿼리와 문서를 동일한 인코더로 임베딩하기 때문에 (쿼리, 문서) 를 쌍으로 임베딩 할 필요가 없으므로 쿼리, 문서를 독립적으로 임베딩하는 것이 가능하고, ANN(Approximate Nearest Neighbor) 기법과 같은 알고리즘을 적용할 수 있는 장점도 있다. 그러나 성능은 쿼리와 문서를 함께 넣고 비교하는 cross-encoder 방식보다 떨어질 수 밖에 없기 때문에 retrieval 된 결과에 추가적으로 성능 좋은 cross-encoder 혹은 LLM 기반의 reranker 를 두어 reranking 하는 것이 성능 향상에 도움을 주는 것이다.
보통 retrieval 할 때에 지원 가능한 top-K 보다 더 많은 개수의 문서를 검색해오고, 이후 reranker 를 통해 실제 주입할 문서만큼을 reranking 하는 것이 일반적이다. 실험에서도 아래와 같은 순서로 reranking 을 적용하였다고 한다.
- 초기 검색으로 상위 150개의 청크를 가져온다.
- 상위 N개의 청크를 사용자 쿼리와 함께 reranking 모델을 돌린다.
- reranking 모델이 리턴하는 스코어를 기반으로 상위 20개의 결과만을 선택한다.
- 선택된 상위 20개의 청크 결과를 컨텍스트로 답변 모델에 전달한다.
4.1. 성능 개선
다양한 reranker 모델이 존재하지만 실험에서는 Cohere 의 reranker 를 사용했다. 사용자 쿼리로부터 contextual embeddings 와 contextual BM25 의 결과를 합쳐서 top-150 결과를 가져오고, reranking 을 통해 상위 20개의 청크 검색 성능을 측정하였다. 이 때는 청크 검색 실패율을 67% (5.7% -> 1.9%) 까지 줄이는 것으로 나타났다.
5. 결론
- embeddings + BM25 는 embeddings 만 했을 때 보다 성능이 좋다.
- Voyage, Gemini 가 가장 좋은 임베딩 성능을 보였다.
- 상위 5, 10, 20 중에는 20개의 청크를 전달하는 것이 가장 성능이 좋았다.
- 청크에 context 를 추가하면 검색 정확도가 크게 향상된다.
- reranker 를 적용하는 것이 더 낫다.
사실 실험에 사용한 모듈 파이프라인이나 실험 결과는 그리 놀랍지 않은 것 같다. 언급한 특정 방법론을 적용했을 때 성능이 향상된다는 것은 모두 예상 가능한 수준이었고, 파이프라인 역시 Advanced RAG 시스템에서 거의 확정적으로 사용되는 방식이기는 하다. 청크의 개수를 결정하는 실험도 특정 결론을 내리기에는 부족한 수준으로 보이고 raranker 도 다양하게 실험하지 않은 것이 아쉬운 부분이다. (LLM 기반의 reranker 는 실험하지 못한 것으로 보인다.) 다만 청크에 단순 요약이 아닌 문서와 관련된 context 를 추가하였을 때 성능 향상을 보였다는 것이 가장 중요한 결론으로 보이며, context 를 뽑아내는 프롬프트 방법과 문서 전체를 context 추출에 사용할 수 있었던 실험 내용이 의미있는 결과였다. Anthropic 에서 실험을 진행한 만큼 신뢰할 수 있는 결과라 볼 수 있을 듯 하고, RAG 시스템을 구축할 때 인덱싱 코스트를 좀 더 투자할 수 있는 상황이라면 단순 요약을 추가하는 것 보다는 더 좋고 합리적인 방법으로 보인다.
'AI' 카테고리의 다른 글
| [AI] RAGAS 공식 문서(docs) 파악하기 (2) | 2024.11.10 |
|---|---|
| [AI] Mixed Precision Training 이란? (3) | 2024.11.01 |
| [AI] SwiGLU는 어떤 함수일까? (0) | 2024.10.09 |
| [AI] LLM 의 발현 능력 (Emergent Ability of LLMs) (3) | 2024.10.02 |
| [AI] BM25 분석하기 (0) | 2024.10.02 |