RAG 자동 평가 중 잘 알려진 RAGAS 에 대하여 논문과 공식문서를 읽고 정리한 바를 기록해두려고 한다. 우선 첫 번째로 23년 9월에 아카이브에 올라온 RAGAS 논문에 대해 파악한 후, 최근까지 업데이트 되고 있는 공식문서 및 코드 기반으로 한번 더 파악해 볼 예정이다. 이 포스팅은 23년 논문에 대한 내용을 정리하는 것을 목적으로 하며, 이후 업데이트 된 최근 공식문서에서의 내용과 일부 다를 수 있다.
- 논문 링크: https://arxiv.org/abs/2309.15217
- 공식 문서(docs) 정리: RAGAS 공식 문서(docs) 파악하기
[AI] RAGAS 공식 문서(docs) 파악하기
이전 포스트에서 RAGAS 논문에 대해 분석하였는데, 논문 이후에 수정된 내용은 주로 공식 문서에서 확인할 수 있기 때문에 추가적으로 어떤 것이 변경되었나 확인해보려고 한다. 문서에는 Evaluatio
jihan819.tistory.com
1. Introduction
LLM 은 상당한 양의 지식을 포함하고 있지만, 몇 가지 근본적인 한계를 가지고 있다. 그 중 제일 대표적인 것이 시의성 문제인데, LLM 학습 이후 발생한 사건에 대해 정보를 제공하지 못하는 문제가 상당히 치명적이다. 또한, 학습 데이터에 매우 드물게 언급된 지식은 학습에 어려움을 겪는다. 이러한 한계점을 해결하기 위해 이제는 RAG(Retrieval-Augmented Generation) 을 활용하는 것이 일반화 되어 있다. RAG 시스템은 LLM 의 내재 지식으로 답변을 하는 것이 아닌, 관련 문서나 정보를 먼저 검색하여 그 내용을 기반으로 답변을 생성하게 한다. 이를 통해 앞서 얘기한 한계들을 일부 해결할 수 있게 되었다.
그러나 RAG 시스템은 여러 요소에 의해 영향을 받기 때문에 최적화 하는 것이 매우 중요하다. Retrieval 모델의 성능도 중요하고, 사용하는 데이터베이스의 성능, 그리고 LLM 자체의 답변 성능도 매우 중요하기 때문이다. 그러나 각각의 컴포넌트들을 평가하는 것, 그리고 이를 통합한 전체 성능(E2E)을 평가하는 것은 매우 어렵다. 이를 위해 논문에서는 RAGAS 라는 자동 평가 프레임워크를 소개하였는데, 별도의 정답셋 없이도 RAG 시스템을 평가할 수 있는 다양한 지표를 제공하는 것이 그 특징이다. RAG 시스템의 빠른 평가를 기반으로 우리는 타겟 도메인에 맞는 적절한 RAG 시스템은 어떠한 형태일 지 평가가 가능하고, 최적의 시스템을 구축하는 데 도움이 될 것이다.
2. Evaluation Strategies
사람의 레퍼런스 없이 RAG 시스템의 품질을 자동으로 평가할 수 있도록 설계하는 것이 RAGAS 의 목적으로, 평가의 주요 기준으로는 신뢰성(Faithfulness), 답변 관련성(Answer Relevance), 문맥 관련성(Context Relevance) 세 가지가 제안되었다. 참고로, 논문 당시에 모든 구현은 OpenAI API 를 사용하여 gpt-3.5-turbo-16k 모델로 진행되었다.
2.1. 신뢰성(Faithfulness)
Faithfulness 는 생성된 답변이 검색된 context 에 기반하여 사실에 맞게 답변되었는 지를 평가한다. 이는 할루시네이션을 방지하고, 답변이 context 을 기반으로 믿을 수 있는 지 확인하는 데에 중점을 두는 metric 이다.
- 평가 방법: LLM 을 사용해 생성된 답변을 개별 문장으로 나누고, 각 문장이 주어진 문맥에서 추론될 수 있는 지를 각각 파악한다. 이를 위해 LLM 에 특정 prompt 를 입력하여, 각 문장이 문맥에 기반해 "Yes" 혹은 "No" 로 판별되도록 하고, 최종적으로 Faithfulness score 를 계산한다. 최종 score 는 context 에 기반하여 "Yes" 로 판단된 문장 수를 나눠진 전체 문장으로 나누어 계산한다.("Yes" 문장의 비율)
논문에 각 metric 에 대한 prompt 도 설명이 되어 있으나, 그렇게 자세한 형태는 아니고 이 부분은 추후 구현체에서 확인하는 것이 더 정확할 것 같아 옮기지는 않았다.
2.2. 답변 관련성(Answer Relevance)
Answer Relevance 는 생성된 답변이 주어진 질문에 적합하게 응답하는 지를 평가한다. 이 metric 은 답변의 사실 여부를 평가하는 것은 아니며, 답변이 질문과 비교하였을 때 완전한 지, 그리고 불필요한 정보는 없는 지에 초점을 둔다.
- 평가 방법: LLM 에 답변을 입력하고, 해당 답변에서 나올 수 있는 예상 질문을 생성하도록 한다. 생성된 질문과 원래 질문 간의 유사도를 계산하여 Answer Relevance 를 측정한다. 논문에서 사용한 유사도는 OpenAI 의
text-embedding-ada-002모델을 사용하여 모든 질문들의 임베딩 벡터를 구하고, cosine similarity 를 이용하여 구한다. 최종 score 는 평균 유사도 값이 된다.
2.3. 문맥 관련성(Context Relevance)
Context Relevance 는 context 를 평가하는 metric 으로, 검색된 context 가 질문에 필요한 정보만을 포함하고 있는 지를 평가한다. 즉, 불필요한 정보가 적고 질문에 관련된 context 가 높은 점수를 받게 된다.
- 평가 방법: LLM 에 질문과 context 를 입력으로 하여 질문에 답변하는 데 필요한 문장을 context 내에서 추출하도록 한다. context 에서 추출된 문장의 수를 context 전체 문장 수로 나눈 비율이 최종 score 가 된다. context 문장 수가 분모로 들어가기 때문에 불필요한 정보가 많으면 score 는 낮아지게 된다.
3. The WikiEval Dataset
RAG 시스템 평가를 위한 RAGAS 프레임워크가 제안되었다고 해도, 실제 사람이 진행하는 정성평가와의 correlation 이 낮다면 그 가치가 떨어질 것이다. 논문에서는 RAGAS 평가 프레임워크의 유효성을 검증하기 위해 새로 제작된 WikiEval Dataset 을 제안하였다. 이 데이터셋을 가지고 RAGAS 평가 결과와 사람 평가를 비교하는 실험이 진행되었다.
WikiEval 은 최신 정보와 관련된 질문을 다룰 수 있도록 2022년 이후 발생한 사건들을 설명하는 50개의 위키백과를 사용하였다. 각 위키백과 페이지에 대하여 ChatGPT 를 사용하여 질문을 생성하였는데, 질문 생성 시 prompt 를 사용하여 아래와 같은 조건을 적용하였다.
Your task is to formulate a question from given context satisfying the rules given below:
1. The question should be fully answered from the given context.
2. The question should be framed from a part that contains non-trivial information.
3. The answer should not contain any links.
4. The question should be of moderate difficulty.
5. The question must be reasonable and must be understood and responded to by humans.
6. Do not use phrases that ’provided context’, etc in the question
context:생성된 질문들과 위키백과의 내용을 바탕으로 ChatGPT 를 사용해 답변을 생성하였고, 2명의 어노테이터가 Faithfulness, Answer Relevance, Context Relevance 기준에 따라 생성된 답변을 평가하였다. 평가 결과 Faithfulness, Context Relevance 는 약 95%, Answer Relevance 의 경우 약 90% 의 일치도를 보였다고 한다.
4. Experiments
위에서 언급한 WikiEval Dataset 을 사용하여 RAGAS 프레임워크가 실제로 얼마나 유효한 지 실험도 진행하였다. RAGAS 의 평가 기준과 성능을 비교하기 위해 2가지 baseline 을 설정하였는데,
- GPT Score: ChatGPT 에게 각 평가 기준에 따라 0 에서 10 까지의 점수를 매기도록 하는 방식이다. 사실 이 논문에서 언급되지는 않았지만, GPT-judge 기반 평가를 할 때 스코어를 0 에서 10 까지로 하면 점수에 대한 신뢰성이 높지는 않다. 그에 따라 scale 을 낮추는 경우가 더 일반화 되어 있다. (0 ~ 3점, True/False 등의 바이너리 평가 등)
- GPT Ranking: ChatGPT 에게 각 평가 기준에 대해 더 나은 답변이나 context 를 선택하도록 하는 방식이다. 2개의 답변을 제공하여 둘 중 하나를 선택하게 하는 방식으로 적용하였다.
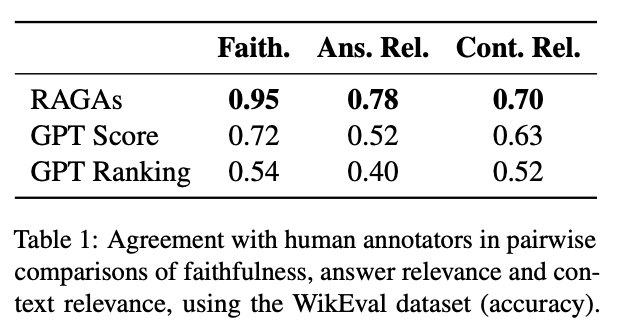
실험 결과 Table 1 에 따르면 RAGAS 는 다른 평가 기준과 비교하여 사람 평가와 높은 일치도를 보였다. 특히, Faithfulness 는 사람 평가와 거의 유사한 매우 높은 정확도를 보였으며, 다른 지표도 0.7 이상의 일치도를 보였는데 이는 RAGAS 가 사람 평가와 매우 유사하게 작동함을 보여준다.