본 글에서는 LLM 등장 이후 RAG 시스템에서의 BM25 관점에서 기술하였습니다.
1. Search의 종류
1.1. BM25 란 무엇인가?
BM25는 NLP 분야 중 정보 검색(IR, Information Retrieval) 분야에서 문서와 쿼리 간 관련성을 계산하는 랭킹 알고리즘이다. 검색 엔진에서 자주 사용되며, 유명한 TF-IDF(Term Frequency-Inverse Document Frequency)를 확장한 형태이다. TF-IDF와 마찬가지로 BM25 또한 term 기반의 검색 방식이라고 볼 수 있고, 단어의 빈도와 중요도를 고려하여 문서와 쿼리의 유사도를 계산하는 방식이다.
1.2. Vector Search
Vector Search(Dense Retrieval, Semantic Search) 는 데이터를 벡터로 임베딩 한 뒤, 주어진 쿼리와 벡터 간의 유사도 (주로 코사인 유사도)를 계산하여 가장 유사한 문서를 찾는 검색 방식이다. BM25와 달리 키워드가 일치하지 않더라도 의미론적으로 유사한 검색 결과를 반환할 수 있는 장점이 있다. LLM 등장 이후 RAG(Retrieval Augmented Generation) 기술이 각광받게 되면서 한동안 Vector Search 방식이 주를 이루게 되었으나, Vector Search 방식은 필요 리소스가 상대적으로 비싸다는 것을 제외하더라도 상용화 시에 몇 가지 문제점이 있다.
- 짧은 쿼리에 대하여 약하고, 쿼리의 작은 토큰의 변화에 대해 쿼리 의도를 담아내기 어려운 경우가 많다.
- 구조화된 데이터를 직접 사용하는 것이 아니기 때문에 결과 해석이 어렵다.
- 임베딩 모델을 의도하는 대로 튜닝하는 것이 어렵다.
- ANN (Approximate Nearest Neighbor) 기법으로 어느정도 해결되었으나 여전히 확장성 문제가 있다.
1.3. RAG 에서의 BM25
위 문제 때문에 RAG 시스템에서 Vector Search 만을 단독으로 사용하기보다는 Sparse Retrieval (BM25)와 Dense Retrieval (Vector Search)를 함께 사용하는 Hybrid Search 방식이 선호된다. 인풋 쿼리에 대해 BM25, Vector Search에 의한 score를 각각 구한 후 2개 결과를 조합하여 최종 스코어를 내린다. score 마다 가중치를 다르게 두어 조합하거나, RRF 방식으로 조합하는 것이 일반적이며, 이렇게 조합된 랭킹 결과는 의미론적 검색 결과와 검색어 (term) 기반 결과를 모두 반영하는 장점을 갖는다. 이후, reranker (cross encoder 혹은 LLM을 활용하여 bi-encoder 기반의 retrieval 보다 높은 정확도)를 두어 검색된 결과에 대해 다시 랭킹을 매기면 그 효과는 극대화된다.
2. BM25
2.1. TF-IDF 의 작동원리
BM25는 TF-IDF와 거의 유사한 형태라고 생각하면 되기 때문에 TF-IDF의 개념을 먼저 이해하는 것이 중요하다.
- TF(Term Frequency): 특정 문서에서 쿼리에 사용된 단어가 얼마나 자주 등장하는지를 나타내는 개념으로, 단어가 문서에 많이 등장할수록 해당 문서가 해당 쿼리와 더 관련이 있다고 판단한다.
- IDF(Inverse Document Frequency): 특정 단어가 전체 문서 집합에서 얼마나 자주 등장하는지를 측정하는 개념으로, 자주 등장하는 단어는 덜 중요한 것으로 간주되어 가중치가 낮아진다. 예를 들어, a, the와 같은 단어는 자주 등장하지만 모든 문서에서 자주 등장하기 때문에 덜 중요한 것으로 간주된다.
즉, 서로 보완하는 2가지 지표를 기준으로 쿼리에 가장 적합한 문서를 찾아낸다.
2.2. BM25 에서는 어떤 부분이 보완되었을까?
TF-IDF는 단순히 단어 빈도와 역 문서 빈도를 곱하는 방식인데, 조금만 생각해 보면 이러한 계산만으로는 다소 부족하다는 생각이 들 것이다. 단어 빈도가 매우 높으면 선형적으로 관련성도 높아야 하는 걸까? 단어의 빈도수와 관련된 지표라면 문서의 길이도 고려되어야 하지 않을까?
아래 수식을 보면서 좀 더 BM25 의 의미에 대해 살펴보도록 하자.
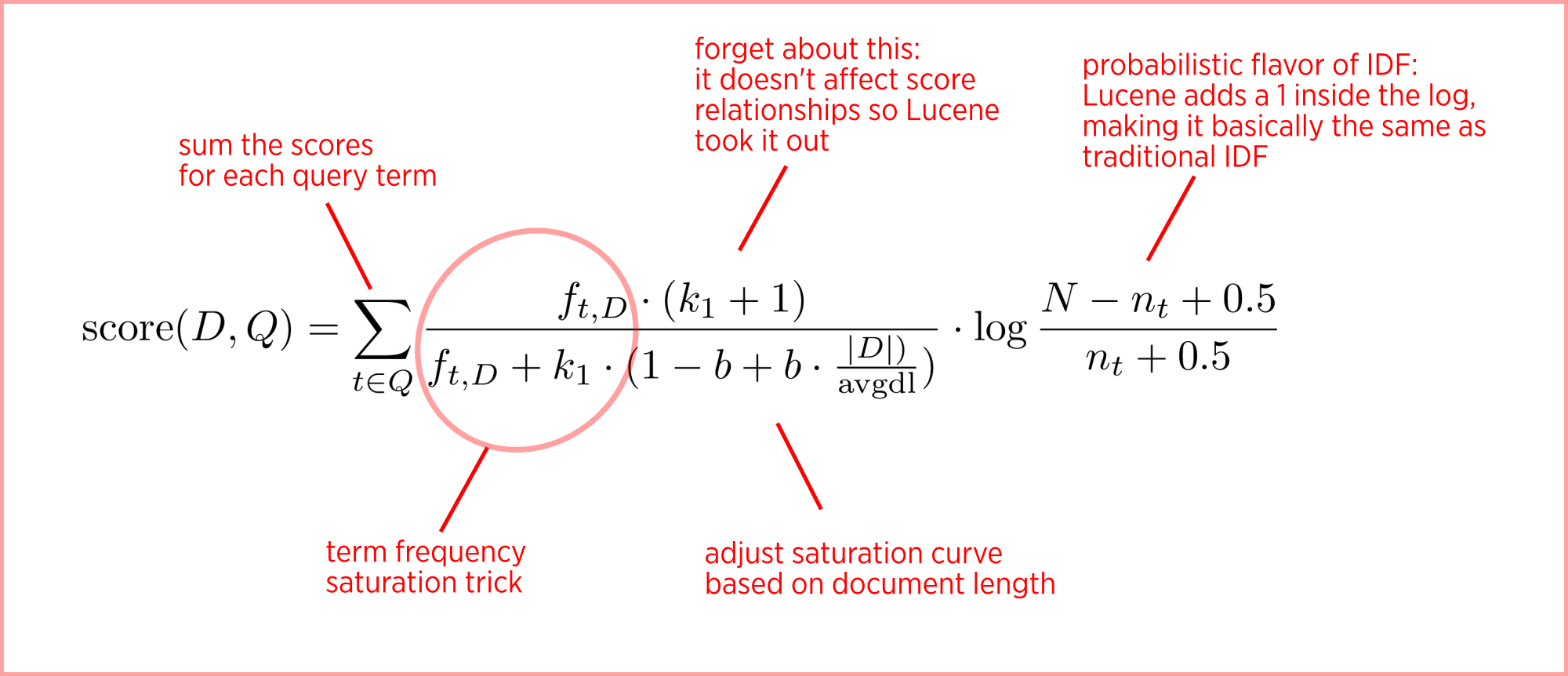
2.2.1. Term Saturation
한 문서에서 한 단어가 2N번 등장하였을 때, N번 등장한 문서보다 2배 더 연관성이 있는 것일까?
충분히 큰 수로 반복이 되는 단어일 때는 그 weight를 줄여서 관련성을 수렴하게 하는 것이 좋을 것이다. 위 수식에서 동그라미 친 부분에 해당하는데, TF / (TF + k) 라고 볼 수 있는 텀이다. 이 값은 최대 1에 가깝게 saturation 되고, k 값에 의해 그 속도가 조절된다. 즉, k 가 커질수록 단어의 수에 따라 값이 천천히 증가한다. 이는 k 가 커질수록 saturation 이 늦게 되고, term 수가 증가할 때 더 큰 가중치를 갖게 된다고 볼 수 있다. k 값은 우리가 조절할 수 있는 파라미터로 일반적으로 1.2에서 2 정도가 추천된다. 아래 그래프를 보면 k 가 커질수록 non-linear 한 성격에서 linear 한 성격으로 변화한다는 것을 알 수 있다.
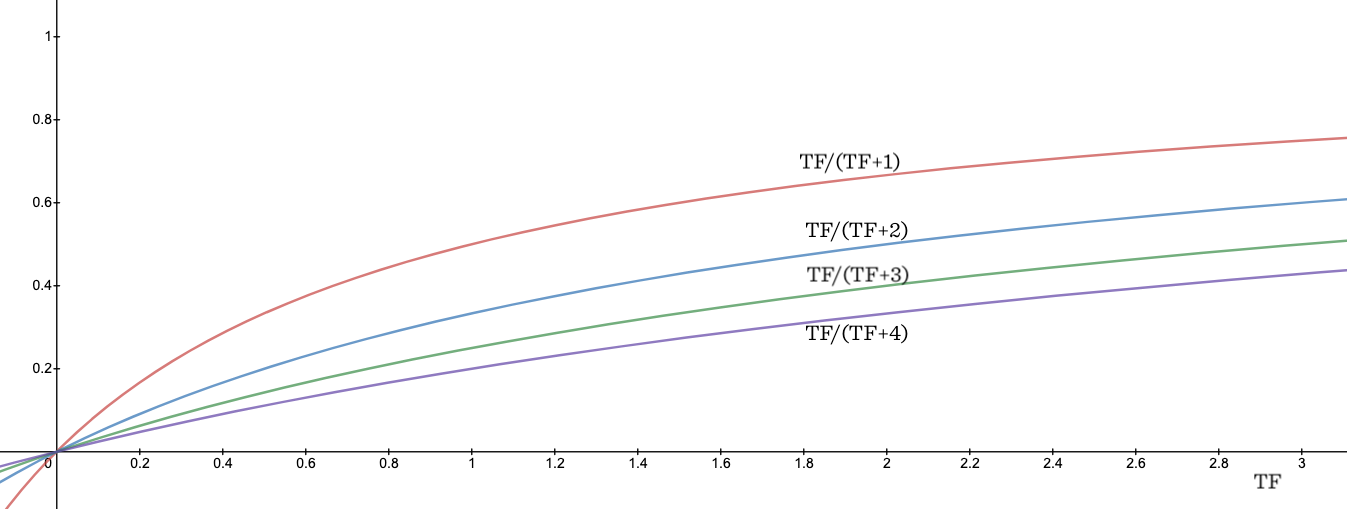
또한, multi-term에 대한 내용으로도 해석해 볼 수 있는데, 일반적으로 하나의 단어가 여러 번 등장하는 것보다 여러 terms들이 골고루 등장하는 것이 더 가중치를 받는 것이 적합할 것이다. 예를 들어, 똑같이 TF가 2가 나온 문서에 대하여 동일한 단어가 2번 등장한 문서보다 다른 단어가 1번씩 총 2번 등장한 문서가 가중치 측면에서 더 높은 스코어를 갖는다.
2.2.2. Document Length
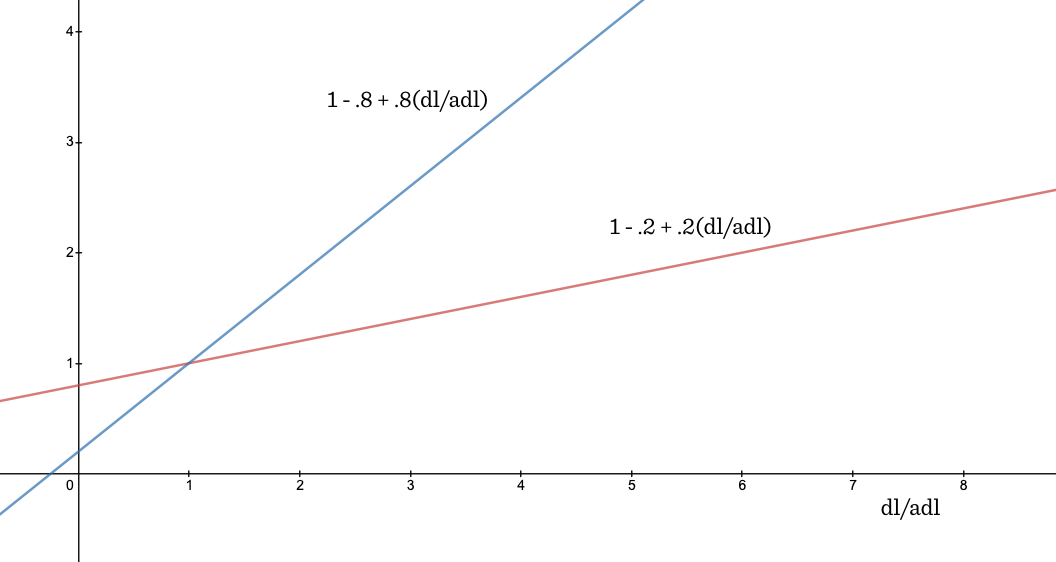
길이가 짧은 문서에서의 단어 등장과 긴 문서에서의 등장이 같은 연관성을 지니는가?
짧은 문서의 경우 등장하는 단어 수에 따라 그 값이 빠르게 증가하도록 만들고, 긴 문서의 경우 느리게 증가하도록 하는 것이 좋을 것이다. 다시 말하면 짧은 문서는 단어 등장 여부에 대한 영향력이 커야 적합한 것으로 해석할 수 있다. 이러한 내용과 관련 있는 수식이 위 수식에서 앞쪽 텀에 해당한다. 평균값 (avg dl)을 기준으로 긴 문서와 짧은 문서를 구분하며, |D| 값이 커질수록 전체 k 값이 커지는 효과가 되어 가중치가 작아지는 효과를 갖는다. 이때, b라는 별도 파라미터를 두어 (0 ~ 1 사이의 값) 조절하는데, b 값이 커질수록 문서 길이에 대한 영향력이 올라가게끔 조절한다.
2.2.3. IDF
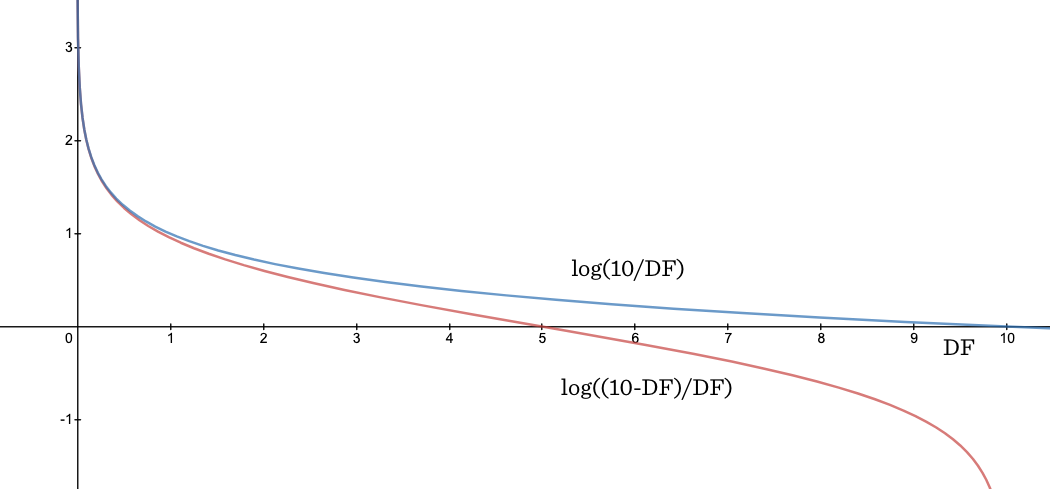
기존 TF-IDF 에서의 IDF와 BM25에서의 IDF는 수식에서 차이가 존재한다. BM25에서의 수식은 2.2에서 확인 가능하다.
- 기존 IDF:
idf(t) = log(n / (1 + df(t))) - BM25 에서의 IDF:
idf(t) = log((N - DF + 0.5) / (DF + 0.5))
여기서 N = 10 일 때의 경우를 보면, 기존 IDF는 10개 문서에 대해 모두 등장한 단어에 대해 IDF 값은 0에 수렴한다. 반면에 BM25에서의 IDF 수식에서는 0을 지나 추가적인 하락이 (sharp drop) 존재한다. 이는 stopword (and, or, the 등)에 대한 가중치를 최대한 낮추기 위함으로, 대부분의 문서에서 등장하는 stopword의 영향력을 기존보다 더 낮추게 된다. 즉, 문서 전체의 절반 이상 등장하는 단어를 negative 값으로 페널티를 줄 것인가, 아니면 0개보다는 나은 것이니 매우 작은 weight 라도 줄 것인가의 차이라고 볼 수 있다.
2.3. TF-IDF 대비 BM25 이 추구하는 방향
- 단어의 출현 빈도가 이미 높은 단어의 경우, 그 영향력을 줄이고 싶다.
- 문서의 길이가 길 때와 짧을 때, 각각 등장하는 단어에 대한 영향력을 다르게 주고 싶다.
- 쓸모 없는 단어 (stopword)의 경우, 영향력을 더 극단적으로 낮추고 싶다.
참조: https://kmwllc.com/index.php/2020/03/20/understanding-tf-idf-and-bm-25/
Understanding TF-IDF and BM-25 - KMW Technology
This post will show you precisely how BM25 builds upon TF-IDF, what its parameters do, and why it is so effective.
kmwllc.com
'AI' 카테고리의 다른 글
| [AI] RAGAS 공식 문서(docs) 파악하기 (2) | 2024.11.10 |
|---|---|
| [AI] Mixed Precision Training 이란? (3) | 2024.11.01 |
| [AI] SwiGLU는 어떤 함수일까? (0) | 2024.10.09 |
| [AI] Anthropic의 Contextual Retrieval (0) | 2024.10.05 |
| [AI] LLM 의 발현 능력 (Emergent Ability of LLMs) (3) | 2024.10.02 |