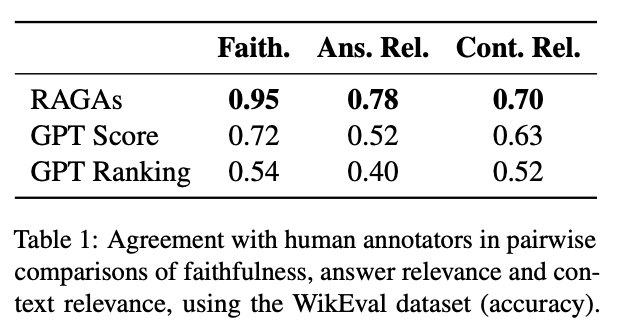
RAG 시스템을 구축하는 경우에 전체 문서를 LLM에 넣을 수는 없으니 일반적으로 원문을 전처리하여 chunking 하여 관련 문서(조각)를 검색해오게 된다. 하지만 많은 경우에 원문이 PDF 문서나 구조화 된 형태(이미지, 테이블 등)이고, 이를 단순 텍스트 추출하여 처리하거나 구조를 무시하게 된다면 답변 시 잘못된 정보를 제공하는 경우가 빈번하게 발생한다. 예를 들어, 테이블을 텍스트 그대로 추출하였을 때 헤더와 값들이 제대로 매핑되지 못하고 밀리게 된다면 관련 문서를 잘 가져왔다 하더라도 잘못된 답변을 제공하게 된다.PDF 파서나 OCR 같은 유용한 도구들을 활용하여 이를 보완할 수 있지만, PDF는 우리가 생각하는 것 보다 훨씬 복잡한 형태가 많고 이를 완벽하게 추출해내는 것은 아직도 매우 어렵다..